How To Choose The Right Database For Your Project
Contents

In this article, you can learn how to choose the right database for your project, from database types to selection criteria and the most popular DBMS of 2023.
Choosing a database for a web app or a mobile solution is not just a business owner’s concern, to be honest. Almost every software engineer is asked this question in a job interview: “What is your preferred database?” What is the correct answer? Or, maybe there’s no correct answer and all this is some psychological test?
Many answers that they choose, like, or prefer database X because they have a lot of experience with it or they managed to create something worthwhile on their last project using it. In some interviews, I heard “I prefer relational databases in 99.9%.” The bottomline: neither of our quick and decisive answers will be fair enough – choosing a database is not a matter of preference.
The great range of database options exists not exclusively for the variety of choice. In fact, each solution addresses a certain issue or set of issues that its counterparts do not cover. To better understand how database selection and software needs are related, we suggest looking at the available database types.
Types of Databases
To start with, let’s make sure we differentiate between the basic terminology – the database and the database management system. Database – is any actual set of some pieces of information – the data. Database management system (DBMS) is a kind of an interface, a software, that allows us to manipulate the database – add, delete, and modify data within it. DBMS vary depending on the data model they are designed to work with in a database. Thus, in many cases, the term “database” is identified with the term “DBMS”, and expression “types of databases” is used to talk about the types of DBMS.
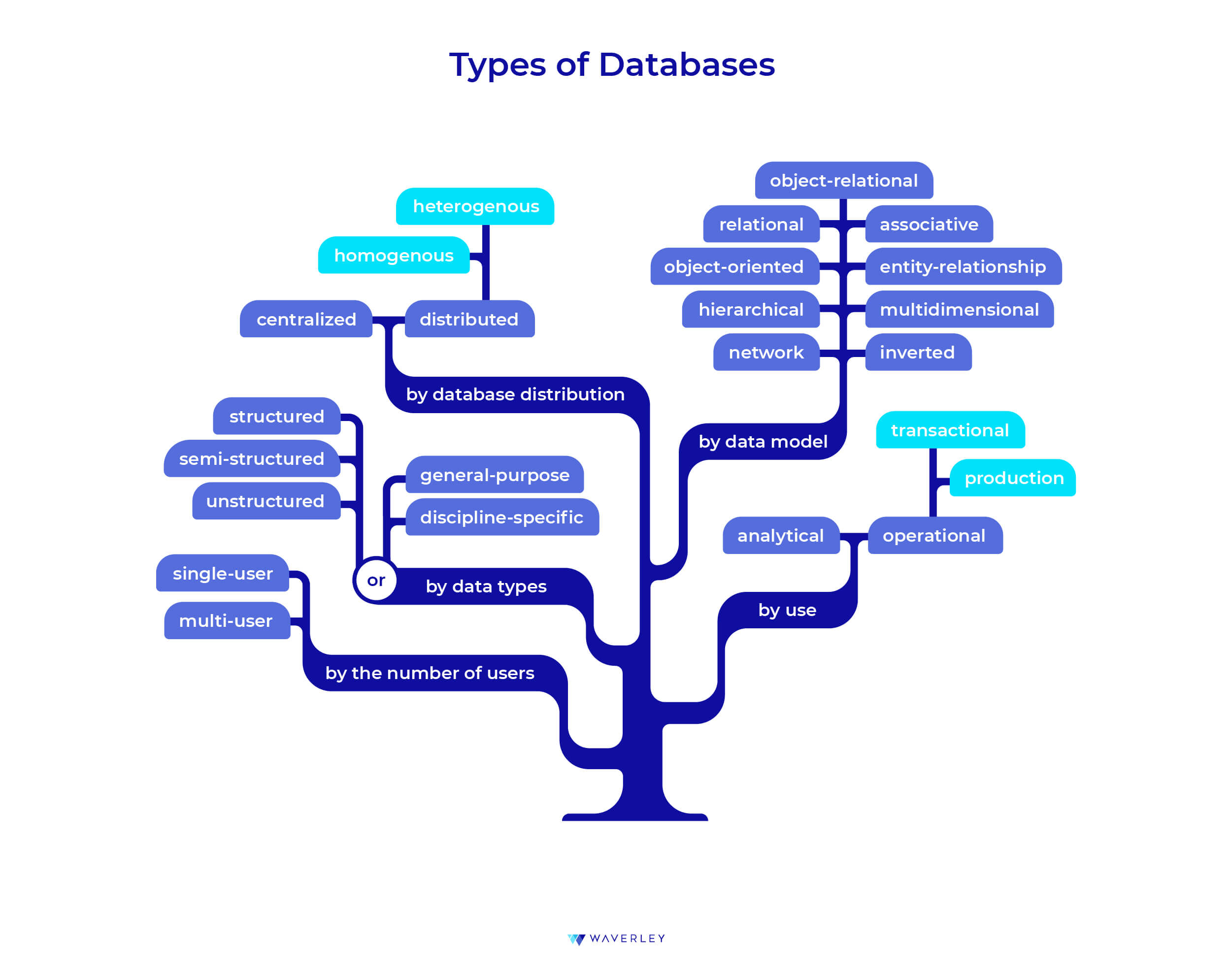
Selecting a database management system, we can differentiate among a great variety of databases types in many ways, depending on the classification principle we choose. For example:
Based on the data model used to structure our data:
- Relational – with data organized in tables related to each other;
- Hierarchical – a tree-like structure, organizing data into parent-child relationships;
- Network – based on the hierarchical model, with the possibility of many-to-many parent-child relationships;
- Object-oriented – store data as objects, for example, JSON documents or media files; meant to conform to the needs of object-oriented programming and multimedia-based software;
- Object-relational – also called hybrid, as it is a mixture of relational and object-oriented approach to database modeling;
- Entity-relationship – data is stored in a way to reflect relationships between entities, their attributes, or processes.
- Inverted index – a data store that organizes a list of identifiers (indexes) of certain data elements within a file, document, or a set of documents – most often applied in full-text search such as we do with search engines;
- Multidimensional – a complex cube-like data structure based on a variation of relational database which is used for data analytics and viewing the same data from different perspectives.
Based on data types stored in them:
- General-purpose – can store any kind of data;
- Discipline-specific – store data, restricted to a specific discipline;
- Operational – used for data involved in real-time operations;
or:
- Structured – for highly organized data which is easily readable for machines and accessible for analytic or other data-consuming tools and applications;
- Semi-structured – used for data that cannot be formatted according to any fixed schema, but does have some markers of separate data elements within, such as emails, HTML code, or graphs;
- Unstructured – for data that cannot be structured following a predefined model, typically includes data and content generated by humans – text messages, posts, comments, various sensor data from wearables.
Based on the database distribution:
- Centralized – a store which keeps a single data file on one computer or server, at a single location;
- Distributed – stores data on multiple servers or computers, in a single or a network of locations, and further falls into two more categories:
- Homogenous – are accessed from the same data management systems and operating systems;
- Heterogenous – accessed from different operating systems, data management systems and based on different data models.
- There are also Cloud databases, which run on a cloud computing platform, i.e. the servers of cloud vendors such as Amazon or Azure or GCP, for example, and typically can be accessed through the SaaS model. They are typically distributed, which is considered more reliable and providing much better performance than centralized databases. The setup and use of cloud databases is tightly related with the cloud development services which are now massively taking over the desktop and mobile-only solutions.
By the number of users:
- Single-user – the one that can be accessed by a single user at a given moment, such as a personal computer;
- multi-user – database designed to be accessed by a multitude of users at the same time, from different devices, which is used by most of modern business applications.
The top reason why there is no one-that-fits-all database solution is because the diverse types of database are each aimed at different goals. This is the first point to keep in mind when choosing the right database management system for your application.
SQL and NoSQL Databases
Another major distinction between different databases appears in the way the software engineers can query the database. That is how they can structure, access, and manipulate the data. And this is one more hint prompting us how to select a database that will suit our project best.
Relational databases
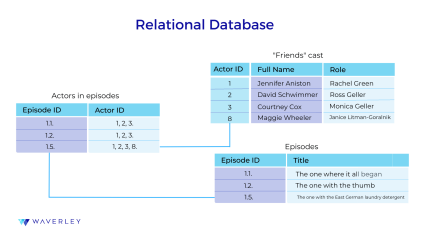
Why do many software engineers prefer relational databases? As you may know, in a relational database, data is arranged in tables of rows, each table related with others. Each data unit having its fixed place and value in a database provides a simple and clear-cut structure to deal with for software developers. Relational databases are also known as SQL databases because of the query language used to manipulate them – SQL.
In addition to simple data structure, the interrelated character of data storage in a relational DB also makes data updating fast. When an element is changed in one table, it automatically gets changed in all other tables containing it. This is also related to the atomicity of transactions occurring in a relational database: a transaction requiring the manipulation of several interrelated data elements is considered as a single and indivisible operation.
These characteristics of a relational database make it the best for web applications and other software systems operating pre-defined and accurate data, such as ID info, personal information, account numbers, transactions, dates, etc. These may include ERP and CRM systems, banking apps, enterprise software, and even gaming software. The most popular relational database management systems are MySQL, PostgreSQL, Oracle, MS SQL Server, Amazon RDS, Amazon Aurora.
NoSQL databases
While SQL databases are clear-cut and convenient when dealing with structured data, they fail to handle unstructured or semi-structured data as well as quickly scale, which have become the main challenges of the modern data-driven world. Thus, the NoSQL types of databases appeared to mitigate the problems of scalability, model flexibility, performance, data diversity and volumes. However, opting for these benefits, we have to sacrifice a more convenient and standardized way of querying.
| Key-value | Document-oriented | Column-oriented | Graph |
|---|---|---|---|
| One key corresponds to one value | Free-format JSON documents | Data sorted by colums | Focus on both data and its relationships |
| Scalable, fast, high-load | Dynamic and flexible | Quick and simple filtering | Simle querying for comlex data |
|
|
|
|
| DynamoDB Redis Memcached | MongoDB CouchDB DocumentDB | Cassandra HBase Azure Tables | Neo4j ArangoDB Dgraph |
Key-value databases
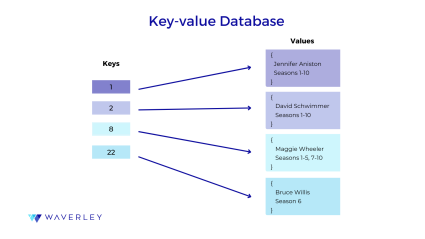
Key-value database is known as the simplest variation of NoSQL databases. In contrast to relational SQL DBs, they can contain data sets that have no predefined structure. This makes them more flexible in terms of data formats they operate – you simply assign a unique key to each data value, and these data values shouldn’t necessarily be of the same format and structure. Calling for a certain key triggers the associated data value.
Such simplicity of key-value databases makes them highly resilient to failure, easy to scale, fast, and high-load. Most often, their structure is used for in-memory databases, which run on a computer’s main memory (RAM), giving them low latency and extremely high throughput at the same time due to the much faster access offered by RAM.
All this makes the key-value in-memory database a good fit for systems requiring quick data access and simple querying. Some good examples of these could be e-commerce solutions (shopping carts, in particular), caching, logging, session management, real-time interactions, personalization functions, and alike. Popular key-value database options include Amazon Dynamo DB, Redis, Aerospike, Memcached.
Document-oriented databases
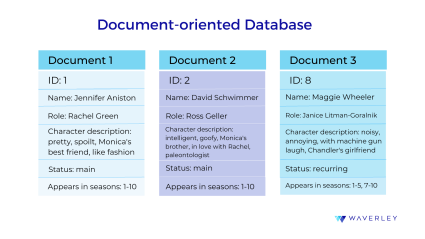
In a document-oriented database, data is stored in the form of documents, typically in JSON format. Each document can have different structure and types of fields, is self-describing and independent of other documents in the DB. This makes document-oriented databases dynamic: its schema shouldn’t be predefined and, moreover, can be easily modified as new data comes in.
Software engineers favor document-oriented databases for their flexibility and scalability. They can be easily adapted to changeable business needs and can store both structured and unstructured data. Thus, document DBs work best for content management solutions, processing big data, mobile gaming, and even IoT applications. Among the top document-oriented DBs, you can find MongoDB, Couch DB, DocumentDB.
Column-oriented databases
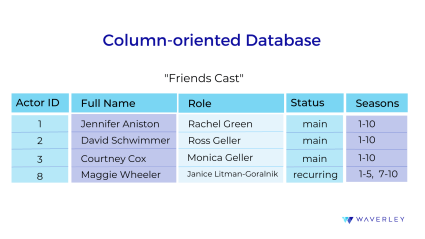
Also known as columnar or wide-column store, this type of database is focused on columns of data, as opposed to rows. In general, the data structure looks similar to a row-oriented database, where each cell of a table row contains different kinds of data about one object. There, when we need to retrieve all the data about this object, for example, an employee information in an HRM system, we can simply call for a single row from the table.
But the situation gets more complicated when we need to filter all the data we have by a certain criteria, for example, find all the employees with the role of a manager. In this case, we need to sort it based on a single column. For a row-oriented database this operation would entail scanning each row for information about the employee role, which is really time and effort-consuming. A column-oriented database will only need to read a single column.
This way, by reading only the needed information in a store, columnar databases require much shorter access time, provide higher retrieval efficiency and more storage size optimization opportunities. Such characteristics make them a great fit for processing big data and analytical workloads. Some examples of columnar databases include Cassandra, HBase, or Azure Tables.
Graph databases
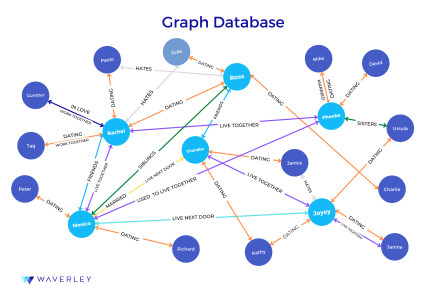
Graph database is a network of nodes connected by edges, the former representing data entities (such as people, accounts, objects) and the latter representing the multitude of relationships between them. Each node can have a number of various relationships with other nodes. This kind of structure makes graph databases a very special type, with relationships between pieces of data equally important to the data itself.
But there are relational databases, what’s so special – you might say. Indeed, relational dbs do store the relationships between pieces of data. But they do it in such a strictly organized and rigid way that querying for complex data relationships may turn into an ordeal.
Just imagine trying to look up the verb “put” and all its relations to other words and linguistic categories in the English language. How much indexing you’d need to include in your query in a relational database in order to retrieve all the possible connections? Meanwhile, in a graph database all these connections would be already reflected with no need for multiple indexing and referencing. Even though this type of database is NoSQL, there’ve been developed several query languages to deal with graph databases specifically, including Cypher, Gremlin, and GraphQL.
Due to the data relationships-oriented approach of the graph databases, they are becoming the core of almost everything related to innovation and data analytics – data intelligence, recommendation engines, fraud detection software, NLP algorithms, machine learning and artificial intelligence, pattern recognition, network management and loads of other emerging applications. Neo4j, ArangoDB, Dgaph are some of the popular examples of graph databases.
SQL vs NoSQL Databases: Comparison
| Features | SQL | NoSQL |
|---|---|---|
| Focus | A well-structured data store, avoiding data duplication, saving storage space | High availability, scaling, inclusiveness, simpler and faster programming |
| Quering | Declarative; restricted by tabular schema; standardised, well-documented, recognizable | Declarative, imperative; flexible, free for adding new attributes; varied syntax, lack standard interface, little consistency across databases |
| Data types/modeling | Rigid: normalized, structured | Flexible: structured, semi-structured, unstructured |
| Data oraganization | In related tables of rows and columns, grouped by common characteristics | Trees, graphs, key-value pairs, rows and columns, documents, don’t need to be related |
| Reliability of transactions | ACID properties:
|
|
| Scaling | Vertical | Horizontal and vertical |
| Support | Massive community Stable codebase | Smaller, fractured community Lack of standartization |
| Access | Mostly proprietary | Many open-source options |
| Compatibility | Available for most platforms | Changeable compatibility |
| Top applications |
|
|
NewSQL
However, NoSQL databases managed to provide a new level of scalability and flexibility in handling data, they still have drawbacks. For example, they cannot satisfy the ACID properties in data transactions that SQL databases do ensure. ACID stands for atomicity, consistency, isolation, and durability of transactions – the key properties that can guarantee data validity at the end of a transaction. And these properties are really important for such sectors as finance and banking, e-commerce, or enterprise management, to name a few.
NewSQL databases strive to combine the advantages of relational and NoSQL databases in order to preserve the ACID properties and relational data modeling principle combined with the horizontal scalability opportunities. The availability of both these features allows to efficiently and reliably work with data of large volumes, which is typical for most modern large-scale applications.
Why not consider NewSQL when choosing a database management system for an enterprise app, for example? The popular examples of NewSQL databases include:
- VoltDB
- ClustrixDB
- Cockroach
- NuoDB
- Altibase
OLTP vs OLAP Systems
Selecting a database for your future application, it’s also important to consider the main purpose of a data store in it. Thus, we can differentiate between the online transaction processing systems (OLTP) and the online analytical processing systems (OLAP).
OLTP systems are designed to record and store transactional data that is data generated during a certain transaction. For example, when such transaction as money transfer occurs, it generates such data as transfer time, location, amount, currency, and so on. OLTP systems are designed to make the capture, storing, and retrieval of data fast, concurrent, and atomic. Thus, the key characteristics of an OLTP database are the following:
- They allow frequent data queries;
- These data queries involve small amounts of data;
- Data is rigorously indexed to enable fast access;
- As a result, response time is minimal, counts in milliseconds;
- They are multi-user and high-load.
OLAP systems are designed for analytical processing of data, that is aggregating transactional and other data followed by its consolidation, drill-down, and slicing and dicing. The result of such processing will be insights, business intelligence, reporting, and forecasting, for example. Thus, in contrast to OLTP systems, OLAP databases are the focus area of data scientists, business analysts, and people involved in complex problem-solving or decision-making.
To find out how data work for OLAP systems, you can study our comprehensive guide on Data Collection for Machine Learning by our Senior Engineer Alex Zubchenko.
To be able to perform such actions with data, OLAP databases have a complex design and querying approach. These systems are based on the multi-dimensional data model, which can be visually represented by a hypercube – each dimension being a separate element of a dataset. The intersections of different dimensions will be the new findings that drive the actual insights in the end. Also, considering the large volumes of historical data OLAP systems process, their response time will be longer.
The most common example of OLAP systems are data warehouses – typically enterprise systems that store large volumes of analytic data for the purposes of reporting, business intelligence, and forecasting. This mostly applies to such industry verticals as commerce and banking, but nowadays is becoming more and more in demand in social media and the entertainment sector to provide recommendations and target ads.
Database Selection Criteria
Having discussed the variety of databases around, we can get down to deciding which one will fulfill the needs of our application in the best possible way. To start choosing the right database for your app, let’s think what will be the main purpose and functionality of our future product. Then analyse it in terms of three main criteria: data availability vs consistency, scalability, and performance.
| SQL | NoSQL | |
|---|---|---|
| The CAP theorem | To provide data cosistency over availability | To provide data availability over consistency |
| The CAP theorem | To provide data cosistency over availability | To provide data availability over consistency |
| Scalability | Complex queries OLTP systems Read operations prevail Structured data | Big Data OLAP systems Write operations prevail Unstructured or semi-structured data |
| Performance | Two-dimensional data that firs into a column-row organization; Frequent but small transactions | Multidimensional data with numerous interrelations, data of different formats; Bulky transactions, complex operations with data |
Availability or Consistency?
To answer the first question, let’s consider the CAP theorem. The CAP theorem states that when dealing with a distributed database (which is mostly the case in modern software), out of three guarantees – consistency, availability, and partition tolerance – only two can be provided simultaneously. How does this work?
Partition tolerance
Any distributed system consists of several nodes. If a node cannot receive any messages from another node in the system, there occurs a partition between the two nodes. In an application, partition can be the result of a network failure or a server crash, for example. Partition tolerance is the ability of the system to continue its operation despite the failure.
Availability
System availability means that every request from the user should elicit a response from the system. Whether the user wants to read or write, they should get a response even if the operation was unsuccessful. This way, every operation is bound to terminate.
Consistency
Data consistency means that the user should be able to see the same data no matter which node they connect to on the system. This data is the most recent data written to the system. So if a write operation has occurred on a node, it should be replicated to all its copies. As a result, users can see that same information when they connect to the system.
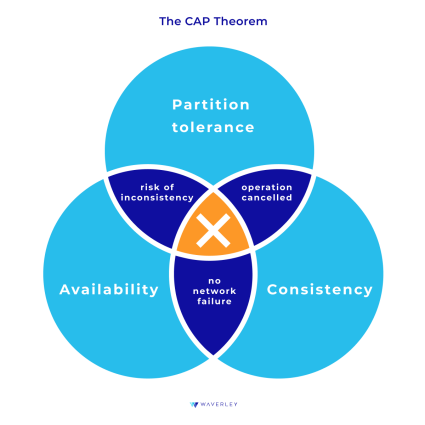
Provided there are no partitions – network or server failures – our system is both available and consistent. But in case of a partition we can either keep it available or consistent. In the first case, the system will stay responsive but without guarantee that all the data across the nodes is up-to-date and synchronized. In the second case, it will return an error or won’t respond but ensure that data is the same for every node.
When choosing a database management system, one of the questions to ask is “what is more critical for your application – data consistency or availability?” This will depend on how often your application makes data updates. Databases with the relational data model at their core, such as SQL or NewSQL databases, are designed with the ACID properties in mind and usually provide consistency over availability. Meanwhile, most NoSQL databases, that follow the eventual consistency philosophy, will cater for data availability.
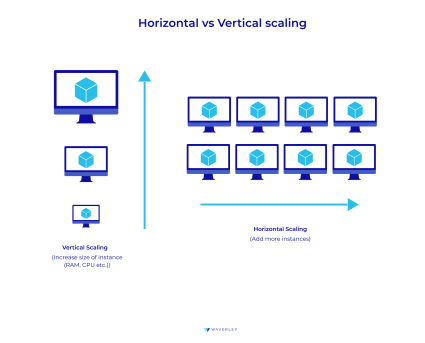
Scalability
At some point of your project, you might realize that your database needs scaling, i.e. extending its capacity to store more data or handle a larger amount if requests, for example. There are two ways databases can scale: vertical scaling and horizontal scaling.
Vertical scaling implies adding more capacity to the system hosting the database by means of configurations, multiprocessors, etc. This kind of scaling is typical of SQL databases which require all data to be stored on one node (server). Meanwhile, horizontal scaling implies adding more servers to the system to increase its capacity. This kind of scaling can be done with NoSQL databases, which store data on distributed servers and you can add as many new servers as you need.
Another important thing is the approach we take when creating an index for a row and how complicated our queries can be. This will affect our database’s scaling capabilities. At the initial development stage, the choice of the database might look quite simple – just choose a database taking into account what type of data you will work with and how you are going to structure it.
But as you move on with your app development trying to add new features, new kinds of data, new user roles, and trying to scale, you might witness as your development has suddenly turned into a headache. For example, our choice is Cassandra, which is a NoSQL columnar database type. If, according to new product requirements, we need to make a complex query to collect all data, we will face a bottleneck as this database is not fully suitable for complex queries with various additional conditions.
Or let’s take MongoDB and start building links between its different collections in the code. We can take a relational database and rest on the fact that our object has 15 options for details, and in order to have a normalized database, we will have to create 16 tables and decide which one to write the details from the code. You can argue that in the new version of relational databases there is a JSON column type. But here you can’t make an index on the field inside it, and writing a request for filtering on it is still a pain in the neck (however not impossible). Another option is to consider the CQRS approach when we have 2 repositories. But, again, this will solve some of our problems – and also add new ones.
So how to choose a database in this case? To solve this dilemma, it’s worth considering the following aspects:
- Are we dealing with big data?
If yes – go for Cassanda or HBase which are both non-relational and columnar, and allow you to make column-based queries efficient for working with big data. They are a great fit for OLAP-based systems, thus being applicable for analytic purposes. - Read or write operations?
In complex applications, different types of databases are not equally efficient in carrying out read and write operations. Also, each application will require a different ratio of read and write operations to be performed, as well as their complexity. Thus, we rely on the CQRS pattern – Command and Query Responsibility Segregation. This means we should have separate database query and command models in a system. For example, the NoSQL document-oriented MongoDB will be more convenient for writing data while the relational SQL database Postgres will be a good choice for querying for data. - How are your business objects structured?
A relational database is very suitable for working with structured data. However, if we deal with unstructured or semi-structured data, this also does not mean that we can only consider NoSQL databases. After all, don’t forget about the JSON cell type in Postgres. What can influence our choice here is the performance of your database considering the size, complexity, and schema of your data.
Performance
When we speak of database performance, we can mean several interrelated characteristics of databases. First of all, performance is about the time it takes for a database to pass a query – latency. The lower the latency – the faster a read or write operation goes through. The influencing factors here are network connection and query complexity.
A way to impact network connection to reduce latency is by hosting our application closer to our database, in the same region, for example. As for the query complexity – it’s closely related to the data types and schemas we are using and how “compatible” they are. For example, we can expect low latency from a relational database when handling two-dimensional data that fits well into a row-column order. But once we need to process more data dimensions, our data transactions may get too hard for an RDBMS to operate fast. In such a case, we can shift our attention to NoSQL.
Another aspect affecting database performance is transaction rate, also known as throughput. The higher the throughput a database can handle, the more users can simultaneously query it without hurdling the speed of processing. Apart from software and hardware features which directly impact a database throughput, we can take into consideration the workloads to be dealt with, for example:
Are these frequent but small transactions as in an oline banking app or less frequent but bulky ones, as in a recommendation engine?
– OLTP-based databases are designed to handle such workloads well. Go for a highly-structured SQL or a key-value database that runs in-memory.Does a transaction include any data sorting, filtering, search by keywords, or other modifications?
– Wide-column databases are designed in a way that allows less resource consumption and better data compression.Will the workload depend on a region, time of the day, season of the year?
– Database distribution across more clusters can help spread the unexpected workload bounces evenly and save performance.
Are you more certain now about which kind of database could be more suitable for your web or mobile app? We hope you are. But this is not it!
Tips for Choosing a Database
The above paragraphs give us plenty of food for thought in considering how to choose the right database for a project. There is a number of factors to take into account, including both the requirement for the software we want to develop and the variety of features that different types of databases and platforms can offer. But where to start? Let’s draw some steps that might help you move along the decision path in the right direction.
Define your product
First and foremost, data will be the “content” of your application, while the app functions will be “shaping” and “modifying” it. A portion of the data will be operational, meaning users won’t interact with it, but it will be key for your system to work as intended. So you need to make it clear how your future app will use all this data:
- The size and types of data which needs to be stored;
- The average amount of data per transaction;
- The frequency of transactions;
- The read to write operations ratio, which type will prevail;
- How rapidly the data will scale;
- Availability or consistency in case of a network partition;
- The data models that your data can fit naturally and whether you might need to change your data schemas.
Some characteristics of your future software can also affect your choice of a database:
- Whether your system is OLTP or OLAP-based;
- The amount of users it will need to handle normally and at peak loads;
- The “geography” of your user base;
- Your application’s domain requirements to data security;
- The programming languages and approach used to develop your app;
- Other systems that your database will integrate with – whether they are compatible with each other.
There are also some non-tech and more business-oriented factors that can impact your choice of a DBMS:
- The budget you are ready to allocate to the necessary licensing and support and the Total cost of Ownership of the system. In addition to direct expenses, you might have to take care of staff training, security costs, ongoing support, handling upgrades, and so on. There are both open source and proprietary options offering a variety of solutions ranging from minimal interference to complete database maintenance and support.
- Time and resources you can afford to handle disaster recovery – some DBMS take longer than others to back up and restore.
- Vendor preference: if your business has already started a partnership with a specific technology vendor, you might be likely to go for their database offers to save some costs and get better deals. This also may include the level of trust and the support quality a vendor can provide.
- Speaking of open source products, a good question to ask yourself is how mature the supporting community is and how likely you will be to find solutions to challenges or issues that may arise.
To sum up this point, the best recommendation would be to conduct a thorough business analysis of your future software product before starting any system design and coding. This will help you understand the solution’s real needs and capabilities and, as a result, better formulate your technical requirements. Our Lead BA Alla Nabatova explains the importance of the product discovery process in her recent article Why Business Analysis is Important in Software Development.
Consider more than one database
The more functions and interactions your system will be offering to its users, the lower the chances that a single way of modelling your data will cover your application needs. For example, you can go for an SQL database modeling scheme to store your entities and all information about them. SQL type of database is also very convenient for frequent updates and write operations.
But what if you want your product to be able to find relationships between your entities and provide recommendations to your users based on these relationships? This will be a great use case for a graph database. Thus, you can make use of two database types. SQL database will be your canonical database – the primary store of all your data. Then, you can index your SQL database entities in your graph database to make things work as you need. The latter won’t own the entities and you won’t be able to use it to update your data – you will have to make it through your canonical database. But it will complement the capabilities of the former to boost your product’s functionality.
On the other hand, integrating different data models means more potential of a failure or inconsistency. This will require involving more experienced and qualified system architects and database administrators to correctly set up your data flows. As a result, be ready for more expenses on the software development and devops services.
Think about the human resources
Choosing a database platform, we should remember that in any case it is not self-supporting. Computer systems, especially the ones with complex design, require human interaction and control. Therefore, your decision will also include the amount and qualification of staff needed to take care of your database:
- A database tech consultant (Database Engineer, for example) to help you analyze your needs for data storage and choose from the available solutions if you are not a tech person or do not have an in-house domain expert.
- A Business Analyst and Solution Architect to conduct a system assessment, propose and evaluate possible solutions, including the approximate Total cost of Ownership, expected team composition, other technologies to be involved, etc.
- Human and tech resources you might need to involve for system setup, implementation, and data management: Database Designer, Database Administrator, Data Engineer(s), Software Engineer(s), DevOps, Support and Maintenance specialists, as well as additional free or proprietary tools, framewords, and libraries to help keep your database and software running and up-to-date.
- If you are willing to move or keep your database and system management in-house, you will also need to arrange knowledge-transfer sessions, staff training, or consider hiring additional domain specialists to your organization.
Most Popular DBMS of 2022-2023
According to Statista’s 2022 report on the most popular database management systems worldwide, the top four positions are taken by the SQL databases – Oracle, MySQL, Microsoft SQL Server, and PostgeSQL. The document-oriented MongoDB takes the fifth place, followed by the key-value Redis, relational DB2 by IBM, full-text search engine Elasticsearch, relational Microsoft Access, and embedded database engine SQLite.
The top 10 positions make a hint that relational SQL database management systems do prevail in the world of software development, with several exceptions. Let’s take a look at them.
Oracle

Oracle Database is a proprietary multi-model database management system which was the first commercially marketed relational DBMS. Nowadays, apart from the relational model, it supports the features of the in-memory columnar store, object-oriented databases, and JSON documents, and provides multi-tenant architecture. It can also cater for the OLTP, DW, as well as mixed workloads, and be available on-premises, on-cloud, and as a hybrid database. Probably, this set of the most demanded and universal characteristics of the Oracle Database take it to the top position in the list.
MySQL

This is a purely relational DBMS which can be available as either open-source or proprietary product. Most often, MySQL is used in combination with other DBMS in products that require the capabilities of a fast, stable, and high-performance relational database. Thus, it’s widely used by many modern traffic-heavy and database-driven web giants, such as Facebook, Twitter, Youtube, Drupal, Joomla, and WordPress.
Microsoft SQL

Another commercially marketed relational database that is designed by Microsoft to serve the data storing and reading needs of other software applications connected to it. It offers a multitude of editions with various features and capabilities to satisfy different customer needs. For example, large data volume storage for enterprise, low-budget hosting for web apps, platform-as-a-service solution for cloud storage, and so on.
PostgreSQL

Also known as Postgres, this database is a representative of SQL database management systems, which also supports JSON querying, implementing transactional processing and ACID properties along with high fault tolerance. It is free and open-source, which allows flexibility, customization, additional security provisioined by the supporting community, low costs, and quick development of the system, making it a strong competitor to the commercial offerings. Postgres is also supported by AWS through Amazon RDS.
MongoDB

The first NoSQL database in this list, MongoDB is a document-oriented source-available DBMS which stores unstructured data in the form of JSON documents. It provides regular expression searches, field queries, and range queries, field indexing, high availability and load balancing due to the support of multiple data replica sets on running on multiple servers. MongoDB’s Aggregation Pipeline enables performing relational-like document processing, allowing grouping, sorting, filtering, and restructuring of the retrieved documents.
Redis

Also a NoSQL DBMS, Redis is an open-source in-memory key-value database. Due to its design, it functions as both data store and cache, providing high performance, scalability, and support for a variety of data types – strings, lists, sets, hash tables, geospatial data, as well as JSON, graph, time-series offered by Redis modules.
IBM Db2

Db2 developed by IBM is an entire family of database management systems, distributed under the commercial license. It is designed to support relational, object-relational and object-oriented features for transactional workloads. Db2 is known to be a highly flexible, efficient, scalable, reliable and secure DBMS, well-fitting for complex and AI-based applications.
Elasticsearch

Elasticsearch is nowadays the most popular enterprise full-text search and log analytics engine, providing such features as multitenancy, near-to-real-time search speed, and search scalability. It’s source-available solution, also available as cloud-based SaaS Elasticsearch Service. Elasticsearch is a NoSQL database, with data being retrieved through Elasticsearch API and data analytics functionality available due to the ELK Stack that also includes the Kibana dashboard and the Logstash data processing pipeline.
Microsoft Access

Microsoft Access is another relational DBMS powered by Microsoft which also offers a graphical user interface and development tools. In contrast to MS SQL Server, MS Access is intended for handling modest volumes of queries for small applications and non-expert users.
SQLite

This is an embedded relational database engine which software developers use as a library, embedding it into the application. Thus, SQLite is known to be the most widely deployed database, used by top web browsers, operating systems, mobile and other devices. It is designed to avoid such drawbacks of client-server databases as need for extensive configuration and administration, operation latency, and inter-process communication.
Conclusion
Having the multitude of points to consider, there is no universal answer to the question what database to use or which one is our favorite. Each type of database has a certain purpose at its core which should correspond to the nature of your data and the product’s business needs. Based on the knowledge about the types and characteristics of various databases we can only draw some general conclusions, for example:
- In many cases, if we do not have to work with big data but have to deal with simple and frequent queries, we can choose a relational database. However, close-knit relationships of your system’s entities will be a more important factor in opting for a relational database. The expected data volume and performance may vary among different vendors.
- For workloads related to big data and data analytics that means not very frequent but complex queries, the right database would be a NoSQL graph database, such as Neo4j.
- If you are looking for a database able to handle a lot of requests, the best option can be Cassandra or HBase, which are columnar read/write-optimized databases and can handle enormous number of requests. On the other hand, unless you are using any data processing technologies, such as Flink or Spark, the relational Postgres or document-oriented MongoDB can be a good choice as well.
At the same time, we must keep in mind that such conclusions cannot apply to every specific use case. Every software application is unique in its own way and the best solution is to take an individual approach. Frankly speaking, choosing the right database is not a piece of cake for any business owner, so you will only benefit from assigning this task to professionals. Tech experts at Waverley Software will gladly guide you through this complicated process.
Finally, it’s important to remember and be ready to accept this fact: on any project, there might come a time when software engineers will tell you that your project needs another type of a database. In the end, a lot depends on timeframes and budget and we always have to balance between different trade-offs when building software.
FAQ
How do I choose between an SQL and NoSQL database?
Since SQL databases provide a standartized data query mechanism which guarantees more stability, data integrity, and follows the ACID principle, you can most likely opt for SQL when building an application involving complex queries and frequent transactions. Meanwhile, NoSQL databases are coping well with quick and frequent scaling, constant adding of new features, data model changes, processing unsctructured and semi-structured data, and large data volumes.
These are the basic aspects to consider when choosing the right database for your application, however, there are many other factors that can influence your choice. If you’d like to get a deeper understanding of your product needs, our technical experts will gladly consult you or arrange a product discovery phase for your project.
Which database is faster?
To answer this question, it’s important to know the types and volumes of data to be stored and processed, the kind of processing it will undergo (transactional or analytic), how frequently it is going to be updated and modified, the number of users and systems accessing this data at the same time. Even your hardware and software capacity will play a role.
Although, roughly speaking, the simpler it is to query the database, the faster it gets and returns the data. The design and data models used in column-oriented, document-oriented, and key-value stores make them some of the fastest databases in terms of data retrieval, provided they are used as intended. The most widely known examples of those are Cassandra, MongoDB, and Redis.
Which type of DBMS is most commonly used?
Based on our initial presumption as well as some stats, we can say that relational (or SQL) databases are the most commonly used ones. They are clear-cut, rigid, and highly reliable, which makes them the best databases for websites and applications requiring ultimate data structuring, consistency, integrity, and accuracy. In most cases, relational database is a primary database on the project, complemented with other types of DBMS for data and operations which are not compatible with the relational model. Probably this fact makes this type of databases so widely used. For example, Facebook uses MySQL as primary database to store social data but they also employ a whole set of NoSQL databases for caching, analytics, searches, filtering, recommendations, and other functionality of the platform.